Motivation
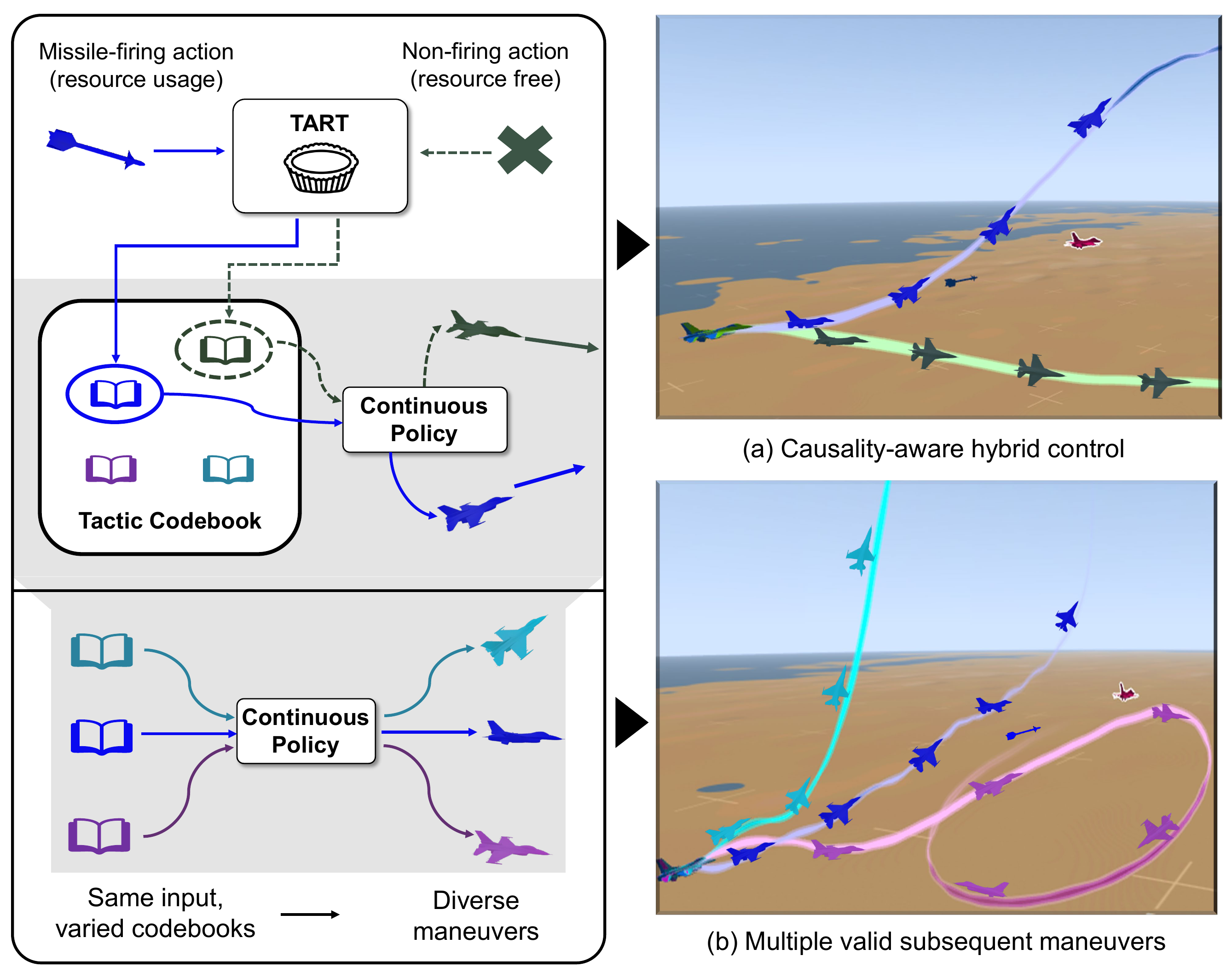
Autonomous robotic systems must coordinate discrete resource usage with continuous maneuvers under limited budgets, especially in fast-evolving tactical scenarios. Prior hybrid-action RL methods often neglect two critical properties: causal dependency between resource decisions and subsequent maneuvers, and the multi-modality of valid follow-up behaviors under the same discrete choice.
Approach
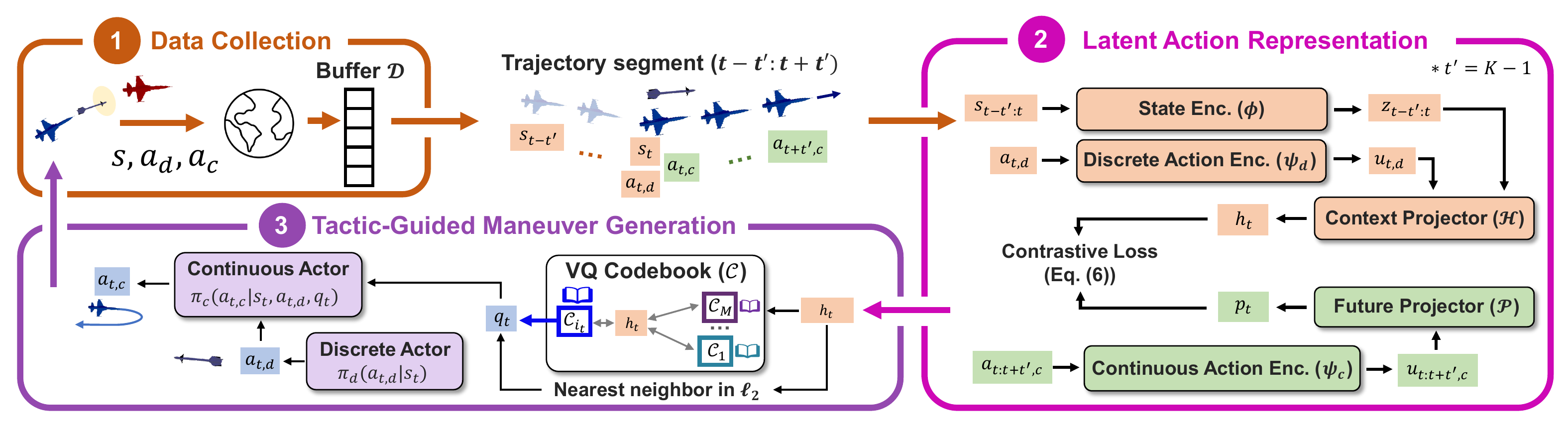
We propose TART (Temporal Action Representation learning for Tactical resource control and subsequent maneuver generation), a framework that learns temporally grounded representations for hybrid action policies by modeling the conditional distribution of continuous maneuvers given recent state history and the current discrete resource decision.
Method
TART maximizes a mutual information objective using an InfoNCE contrastive loss that aligns matched context–future trajectory pairs. The resulting context embeddings are vector-quantized into a compact codebook of tactical modes, which condition a factorized hybrid policy: discrete actions select a tactical mode, and the continuous actor generates a multi-modal maneuver distribution under that mode.
Results
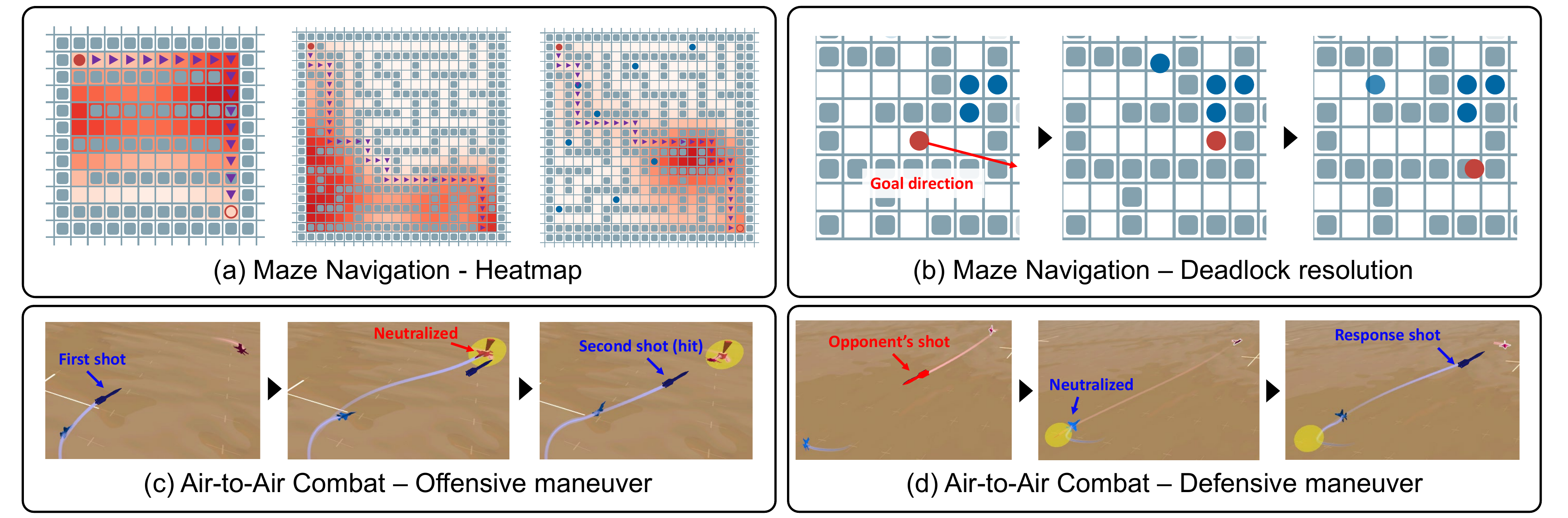
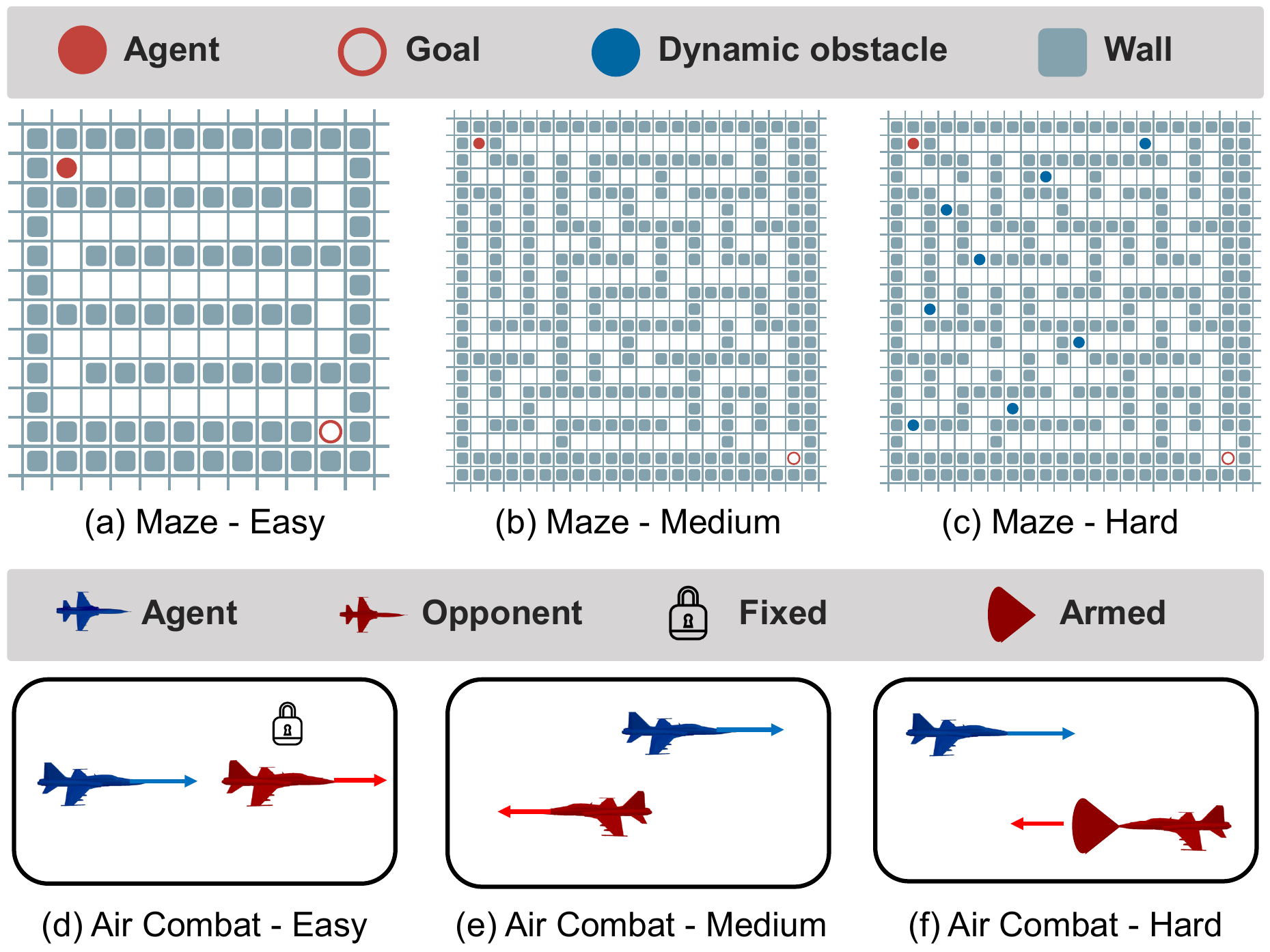
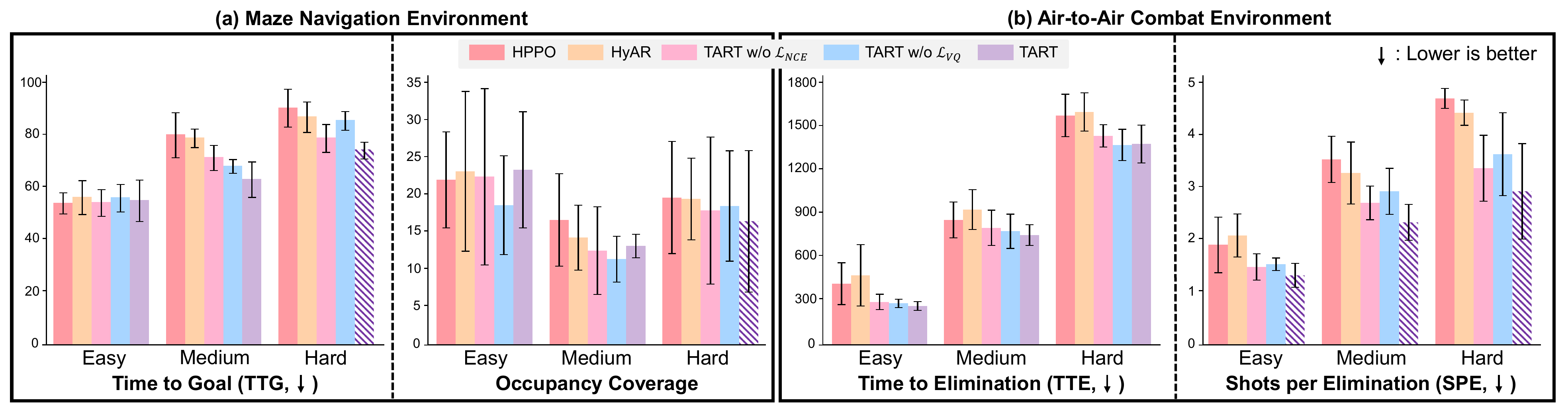
We evaluate TART in two resource-limited domains: (i) budgeted maze navigation with discrete Boost and Penetration options, and (ii) high-fidelity F-16 air-to-air combat with missile and defense system deployment. TART consistently outperforms PADDPG, PDQN, HPPO, and HyAR in success rate while maintaining or improving resource efficiency (TTG, TTE, SPE), demonstrating effective temporal coupling between resource control and subsequent maneuvers.